Prometeus: Enhancing cybersecurity with PROtocol MEssage analysis and anomaly detection using TExt UnderStanding
| | ||
| Beschreibung: |
Prometeus ist ein interdisziplinäres Projekt, das an der Hochschule Hannover in enger Zusammenarbeit von Forschenden der Computerlinguistik und angewandten Informatik durchgeführt wird. Der Projektname versteht sich als Kofferwort und bildet den Projekttitel: „enhancing cybersecurity with PROtocol MEssage analysis and anomaly detection using TExt UnderStanding“.
Ziel des Projekts ist die Verbesserung der Resilienz von Cyber-physischen Systemen, insbesondere kritischer Infrastrukturen, gegenüber Angriffen und Störungen durch eine frühzeitige Anomalieerkennung mithilfe von Methoden aus dem Bereich des Natural Language Processing (NLP) und Graph Neural Networks (GNNs). Methoden aus dem NLP werden für die Interpretation von Log-Daten und ihre Transformation in eine Graphdatenstruktur verwendet. Die erstellten Graphen repräsentieren das Verhalten der Systemknoten und -komponenten. Mithilfe von Graph Neural Networks erlernen wir das Normalverhalten, um anschließend Abweichungen davon zu erkennen. Abweichungen werden als Anomalien gemeldet und kontextualisiert, sodass eine Reaktion auf die Meldung frühzeitig möglich ist. Die Ergebnisse der Anomalieerkennung werden in bestehende Sicherheitsarchitekturen integriert. Sie dienen als zusätzliche Informationsquelle für Sicherheitsspezialisten. In der folgenden Abbildung ist ein schematischer Durchlauf durch das zu entwickelnde System skizziert. 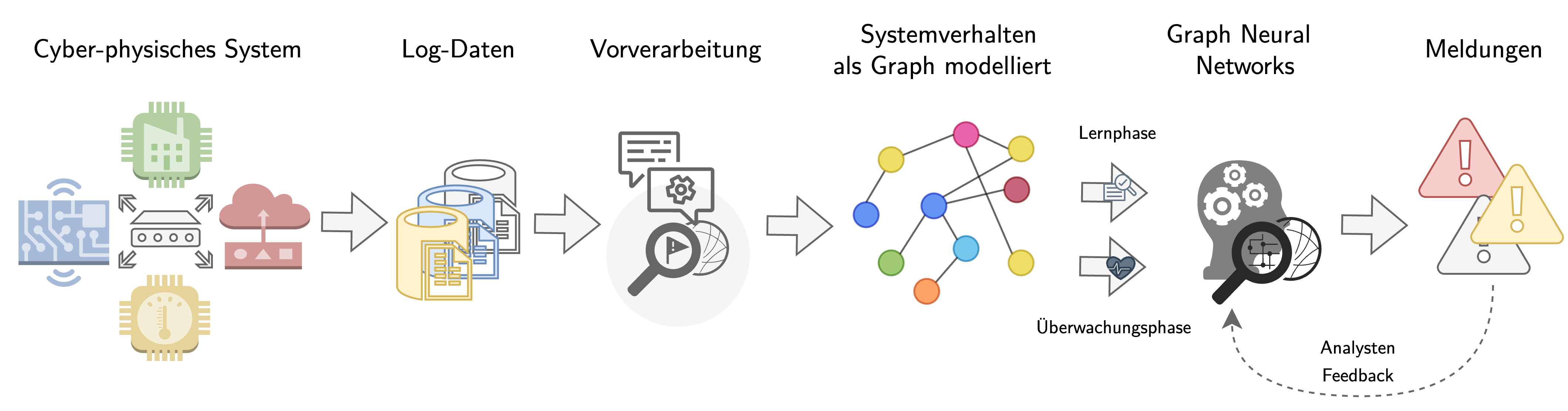
|
|
| Beteiligte: | Prof. Dr. Felix Heine, Prof. Dr. Carsten Kleiner, Prof. Dr. Christian Wartena, Kilian Dangendorf M.Sc., Sven-Ove Hänsel M.Sc. | |

