Vorverarbeitung von Texten mit Python und NLTK¶
Für viele Aufgaben müssen Texte immer auf der gleichen Art analysiert werden. Für eine Aufgabe wie die Sprachidentifikation können wir einen Text als eine lange Zeichenkette betrachten. Meistens brauchen wir aber eine Liste von Wörtern, mit denen wir weiter arbeiten können.
Wenn wir erstmal den Text haben (was oft nicht einfach ist, wenn der Text z.B. aus einer Webseite extrahiert werden muss), teilen wir den Text zuerst in Sätze und die Sätze anschließend in Wörtern auf. In vielen Fällen führen wir die Wörter dann noch auf ihren Grundform zurück, und bestimmen die Wortart für jedes Wort, da diese oft wichtige Informationen für die wietere Verarbeitung gibt. Eventuell folgen dann Schritte, wie das Nachschlagen der Wörter in einem Thesaurus oder das Erkennen von sogenannten Named Entities: Namen von Personen, Institutionen, Produkte, usw.
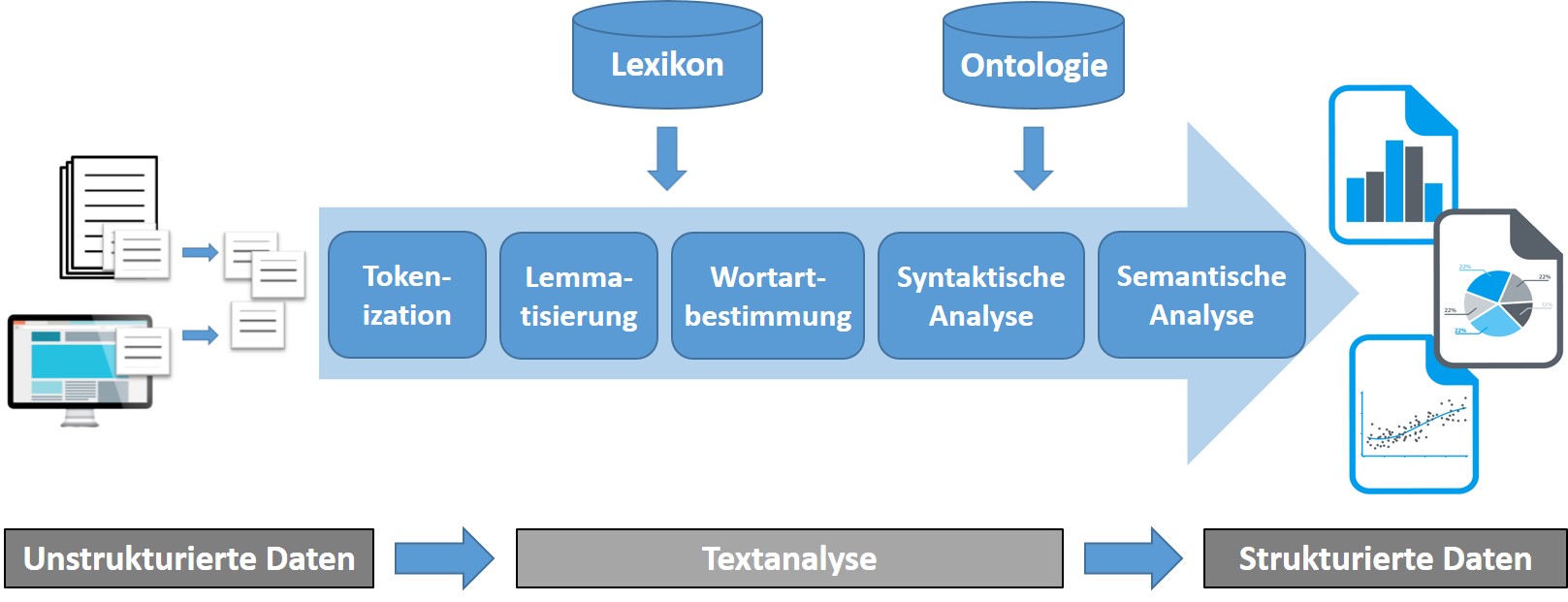
Für die Analyse von Englischen Texten sind weitaus mehr Werkzeuge verfügbar als für das Deutsche. Die Verarbeitung von englischen Texten ist daher etwas einfacher. Das wir außerdem auch of englische Texte analysieren müssen, schauen wir uns die Standardverarbeitung zunächst für das Englische an.
Englische Texte¶
Wenn wir mit Python Texte analysieren wollen, ist das Paket NLTK der Stanford University unverzichtbar. Dieses Paket umfasst State-of-the-Art Implementierungen für so gut wie alle wichtige Algorithmen aus der Sprachverarbeitung und ist in den meisten Python-Distributionen enthalten.
NLTK enthält auch eine große Menge Ressourcen, die Sie nutzen können, oder die manche der bereitgestellten Algorithmen brauchen. Diese sind meistens noch nicht installiert. Das nachinstallieren dieser Ressourcen ist ganz einfach.
import nltk
nltl.download()
Es sollte jetz ein Fernster geöffnet werden. Wählen Sie alles aus dem NLTK-Buch zum installieren aus.
Satzerkennung und Tokenization¶
Mit der Python-Funktion Split() können wir einen Text leicht aufteilen. In vielen Fällen machen wir dann aber Fehler. Es fängt schon damit an, dass Satzzeichen am vorangehenden Wort geschrieben werden, aber nicht dazu gehören, es sei denn, das Wort ist eine Abkürzung oder eine Ordinalzahl, aber letzteres nur im Deutschen. Statt uns über alle Ausnahmen Gedanken zu machen, nutzen wir hierfür einfach eine Funktion aus NLTK. Diese Funktion ist übrigens nicht auf Regeln basiert, sondern wurde aus vielen Beispielen gelernt.
Im nächsten Beispiel sehen wir, wie man mit Python und NLTK eine Zeichenkette in eine Liste von Wörtern aufteilen kann. Wir finden nicht nur Wörter, sondern auch Satzzeichen, Zahlen und Symbole. Der Sammelbegriff für diese Einheiten ist Token. Das Zerlegen einer Zeichenkette in Tokens wird daher Tokenisierung oder auf Englisch Tokenization genannt.
import nltk
sentence= "At eight o'clock on Thursday morning... Arthur didn't feel very good."
tokens = nltk.word_tokenize(sentence, language='english')
print(tokens)
In vielen Fällen ist es wichtig zu wissen, wo die Satzgrenzen sind: Die Wörter in einem Satz haben eine viel engere Beziehung zueinander, als Wörter in verscheidenen Sätzen. Zum Beispiel stehen Begriffe, die aus mehreren Wörtern bestehen, wie "Bundesministerium für Gesundheit" immer innerhalb eines Satzes.
Die Frage ist nun, ob wir den Text erst in Wörter aufteilen und dann in Sätzen oder umgekehrt. Um zu entscheiden, ob ein Punkt ein Satzende markiert, muss man unter anderem Wissen, ob das Wort vor dem Punkt eine Abkürzung ist. Man muss das Wort also schon mal in der langen Zeichenkette erkannt haben. Der Sentence Splitter von NLTK arbeitet aber trotzdem auf ganzen Texten und braucht keine vorangehende Zerlegung in Tokens.
Zum Ausprobieren, lesen wir einen kurzen englischen Text ein. Den hier genutzten Beispieltext finden Sie hier: http://textmining.wp.hs-hannover.de/texte/hanover.txt . Der Text ist der Wikipediaseite http://en.wikipedia.org/wiki/Hanover.html entnommen.
import nltk
import codecs
textfile = codecs.open("texte/hanover.txt", "r", "utf-8-sig")
text = textfile.read()
textfile.close()
sentences = nltk.sent_tokenize(text,language='english')
tokenized_text = [nltk.word_tokenize(sent, language='english') for sent in sentences]
print(tokenized_text[0])
print(tokenized_text[5])
Wortarterkennung (Part-of-Speech Tagging)¶
Die Wortart eines Wortes gibt oft wichtige Informationen. Den Hauptinhalt eines Textes erkennen wir beispielsweise schon an den benutzten Substantiven und Verben, während Adjektive und Adverbien wenig beitragen, und Artikel, Präpositionen und Hilfsverben hierzu überhaupt keine nützliche Information liefern.
Wortarten werden im Englischen Part of Speech genannt, ein Programm, dass die Wortarten zuweist, daher Part of speaach tagger oder einfach POS tagger. Der NLTK enthält einen guten (statistischen) POS Tagger.
Die Wortklassen, die dieser Tagger zuweist, sind nicht genau die, die Sie in der Schule gelernt haben. Manche Klassen sind unterteilt, es gibt Tags, die neben der Wortklasse weitere Informationen, wie z.B. 3. Person Singular enthalten und es gibt Klassen für Wörter, die oft schwierig einzuteilen sind. Die Tags, die im folgenden Beispiel genutzt werden, sind die aus dem sogenannten Pennsylvenia Treebank Tagset. Eine Beschreibung der Tags sowie Beispiel dafür bekommen Sie mit der help Funktion:
nltk.help.upenn_tagset()
Jetzt aber ein Beispiel für den Tagger:
tags = nltk.pos_tag(tokenized_text[0])
print(tags)
Lemmatisierung¶
In vielen Sprachen, wie auch im Deutschen und Englischen, können Wörter in verschiedenen Formen auftreten. (Es gibt auch Sprachen, in denen das nicht der Fall ist. Diese Sprachen werden isolierende Sprachen genannt. Beispiele hierfür sind Mandarin (Chinesisch) und Vietnamesisch)). Oft ist es wichtig, den Grundfom eines Wortes, das im Text in flektierter Form vorkommt, zu bestimmen. Es ist wichtig, dass wir hier drei Begriffe klar trennen:
- Lemma - Die Form des Wortes, wie sie in einem Wörterbuch steht. Z.B.: Haus, laufen, begründen
- Stamm - Das Wort ohne Flexionsendungen (Prefixe und Suffixe). Z.B.: Haus, lauf, begründ
- Wurzel - Kern des Wortes, von dem das Wort ggf. durch Derivation abgeleitet wurde. Z.B.: Haus, lauf, Grund
Wir unterscheiden jetzt Stemmer, Programme, die den Stamm eines Wortes suchen, und Lemmatisierer, die das Lemma für jedes Wort suchen. Manche Stemmer trennen auch produktive Derivationssuffixe ab, und geben in vielen Fällen nicht den Stamm, sondern den Wurzel eines Wortes. Es wird oft davon ausgegangen, dass dies für Information Retrieval von Vorteil ist. Wenn man beispielsweise nach analysieren sucht, möchte man wahrscheinlich nicht nur Ergebnisse mit analysiere, analysiert , analysierende, usw. haben, sondern vermutlich auch welche, in denen nur das Wort Analyse vorkommt. Man kann aber genau so Negativbeispiele finden. Ob diese Art von Stemming wirklich nützlich ist für Information Retrieval, ist nicht eindeutig gekärt (vgl. z.B.: BRANTS, Thorsten. Natural Language Processing in Information Retrieval. In: CLIN. 2003.).
Ein guter Lemmatizer, der im NLTK enthalten ist, ist der WordNet-Stemmer, der die Vollformen einfach im online-Wörterbuch WordNet nachschlägt. Da ein Wort im Englischen oft zu mehreren Klassen gehören kann, braucht der Wordnet-Lemmatizer auch die Wortklasse. Wir brauchen jetzt ein paar Zeilen Code, um die Penn Treebank Tags in Wordnet-Klassen zu übersetzen:
from nltk.corpus import wordnet as wn
lemmatizer = nltk.WordNetLemmatizer()
def wntag(pttag):
if pttag in ['JJ', 'JJR', 'JJS']:
return wn.ADJ
elif pttag in ['NN', 'NNS', 'NNP', 'NNPS']:
return wn.NOUN
elif pttag in ['RB', 'RBR', 'RBS']:
return wn.ADV
elif pttag in ['VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ']:
return wn.VERB
return None
def lemmatize(lemmatizer,word,pos):
if pos == None:
return word
else:
return lemmatizer.lemmatize(word,pos)
lemmata = [lemmatize(lemmatizer,word,wntag(pos)) for (word,pos) in tags]
print(lemmata)
Etwas einfacher ist der sogenannt Porter Stemmer. Der Porterstemmer benutzt kein Wörterbuch sondern hat nur eine Liste von Suffixen, die abgetrennt oder ersetzt werden. Dies führt in vielen Fällen zu unsinnigen Ergebnisse. Oft ist das aber unproblematisch, so lange verschiedene Formen eines Wortes auf dem gleichen eindeutigen Stamm zurückgeführt werden. Neben dem Porter Stemmer enthält NLTK den Lancaster Stemmer, der nach dem gleichen Prinzip arbeitet. Schauen Sie sich die Ergebnisse genau an und vergleichen die Sie die STämme mit den Lemmata des Wordnet-Stemmers!
porter = nltk.PorterStemmer()
lancaster = nltk.LancasterStemmer()
print("Porter Stemmer:")
stems = [porter.stem(t) for t in tokenized_text[0]]
print(stems)
print("\nLancaster Stemmer:")
stems = [lancaster.stem(t) for t in tokenized_text[0]]
print(stems)
Deutsch¶
Deutsch und Englsich sind Sprachen, die sich in vielen Hinsichten zielich ähnlich sind. Die Verarbeitungsschritte für einen Deutschen Text unerscheiden sich daher nicht wesentlich von denen für englische Texte. Bei der Tokenisierung und Satzerkennung müssen wir lediglich Deutsch als Parameter angeben, damit besonderheiten des Deutschen besser berücksichtigt werden.
Zum Ausprobieren, lesen wir wieder einen kurzen Text ein. Den hier genutzten Beispieltext finden Sie hier: http://textmining.wp.hs-hannover.de/texte/syrien.txt . Der Text ist der Wikipediaseite http://de.wikipedia.org/wiki/Syrien.html entnommen.
import nltk
import codecs
textfile = codecs.open("texte/Syrien.txt", "r", "utf-8")
text = textfile.read()
textfile.close()
sentences = nltk.sent_tokenize(text,language='german')
tokenized_sent = nltk.tokenize.word_tokenize(sentences[23],language='german')
print(tokenized_sent)
Lemmatisierung und Wortarterkennung¶
Leider enthält das NLTK Paket keine Lemmatisierer und Wortarterkenner (POS Tagger) für das Deutsche.
Wir nutzen hier für beide Funtionen den Hanover Tagger (Siehe: Christian Wartena (2019). A Probabilistic Morphology Model for German Lemmatization. In: Proceedings of the 15th Conference on Natural Language Processing (KONVENS 2019): Long Papers. Pp. 40-49, Erlangen. )
Wir müssen den Hanover Tagger zunächst (einmalig) herunterladen und installieren:
!pip install HanTa
Wir binden das Modul ein und laden ein vortrainiertes Modell:
from HanTa import HanoverTagger as ht
tagger = ht.HanoverTagger('morphmodel_ger.pgz')
Wir können jetzt Wörter oder Sätze analysieren. Die Funktion analyze() gibt ein Lemma und Wortart für eine Wortform:
print(tagger.analyze('Fachmärkte'))
Mit der Funktion _tagsent() werden alle Wörter in einem Satz lemmatisiert und und getagt. Bei Mehrdeutigkeiten, wir die WOrtart gewählt, die im Kontext am wahrscheinlichsten ist. Wir versuchen das mal mit unserem Beispielsatz.
tags = tagger.tag_sent(tokenized_sent)
print(tags)
Weitere Möglichkeiten des Hanover Taggers werden hier beschrieben.
Unser Text ist nicht sehr lang, aber zum Schluss schreiben wir doch noch mal etwas mehr Code und machen noch mal eine nette Statistik:
from pprint import pprint
nouns = []
sentences_tok = [nltk.tokenize.word_tokenize(sent) for sent in sentences]
for sent in sentences_tok:
tags = tagger.tag_sent(sent)
nouns_from_sent = [lemma for (word,lemma,pos) in tags if pos == "NN" or pos == "NE"]
nouns.extend(nouns_from_sent)
fdist = nltk.FreqDist(nouns)
pprint(fdist.most_common(10))
fdist.plot(50,cumulative=False)

Schon bei diesem kurzen Text sehen wir eine Verteilung, die dem Zipfschen Gesetz entspricht!
Alternative: Treetagger¶
Der TreeTagger ist ein statistischer/trainierter Tagger und einer der beliebtesten Tagger für das Deutsche. Der TraTagger ist nicht in Python installiert, wodurch die Installation etwas umständlicher ist. Dafür ist die Analyse wesentlich schneller. Die Distribution enthällt trainierte Parameter für verschiedene Sprachen
Installation¶
- Herunterladen von http://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/
- Zip-Datei einfach entpacken.
- Am Besten in Program Files, im Benutzerverzeichnis oder auf der höchsten Ebene eines Laufwerks.
- Wenn Sie mit Jupyter arbeiten evt. im Wurzelverzechnis Ihrer Notebooks.
- Außer den TreeTagger müssen Sie ein Sprachmodell herunterladen. Die gibt es unter dem Link Parameter Files . Im TreeTagger-Ordner auf Ihrem Rechner legen Sie einen Unterodner lib an. In diesen Ordner kopieren Sie den Parameter File.
- Wir nutzen http://treetaggerwrapper.readthedocs.org um den TreeTagger in Python nutzen zu können.
- Treetaggerwrapper.py von Moodle einfach in das Arbeitsverzeichnis kopieren.
Wenn der TreeTagger nicht funktioniert, können Sie den TreeTagger mit dem Installationspfad aufrufen: tagger = treetaggerwrapper.TreeTagger(TAGLANG='de', TAGDIR='Pfad zum TreeTagger')
import treetaggerwrapper
tree_tagger = treetaggerwrapper.TreeTagger(TAGLANG='de')
tags = tree_tagger.tag_text(tokenized_sent,tagonly=True) #don't use the TreeTagger's tokenization!
pprint(tags)
Wir haben jetzt die Lemmata und die Wortarten gefunden! Die Tags, die der TreeTagger für die Wortartenvergibt sind in den Parameter-Dateien festgelegt. In der Datei, die auf der Webseiite für das Deutsche zur Verfügung gestellt wird, sind das die Tags aus dem Stuttgart-Tübingen Tagset. Eine Beschreibung dieser Tags finden Sie hier: http://www.ims.uni-stuttgart.de/forschung/ressourcen/lexika/TagSets/stts-table.html
Das Ergebnis ist aber der direkte Ausgabe vom TreeTagger und nicht sehr pythonisch. Das kann aber leicht geändert werden:
tags2 = treetaggerwrapper.make_tags(tags)
pprint(tags2)