In der Rechtswissenschaft spielen Texte eine zentrale Rolle und werden im Kontext weiterer Texte interpretiert. In diesem Projekt sollen Verfahren entwickelt werden, um diese komplexen Zusammenhänge innerhalb und zwischen den Texten explizit zu machen. Das Projekt beinhaltet die Entwicklung einer Pilotanwendung, den Aufbau eines Korpusses aus juristischen Texten und die Analyse der Bezüge zwischen den Verträgen. Dabei werden Methoden aus der künstlichen Intelligenz eingesetzt um Verweise zwischen den Texten systematisch zu erfassen.
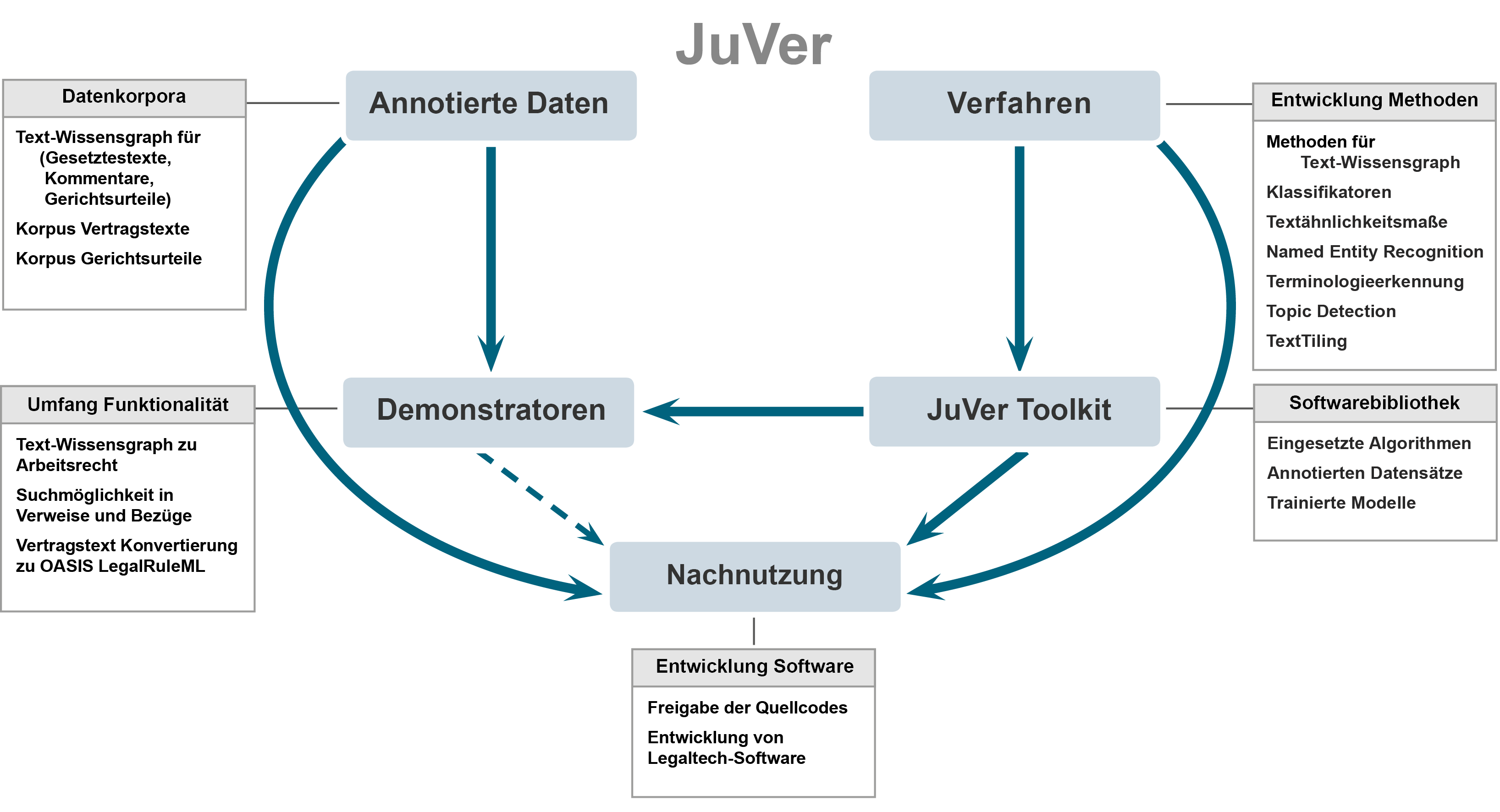
Zu den grundlegenden Problemstellungen im Projekt JuVer gehören hierbei:
Projektleiter: Prof. Dr. Christian Wartena
Verantwortlich Rechtswissenschaften: Prof. Dr. Fabian Schmieder
Wissenschaftliche Mitarbeiterinnen und Mitarbeiter: Frieda Josi M.A. und Jean Charbonnier M.Sc.
Laufzeit: 01.10.2019 bis 30.09.2022 Nachweis: Portal Volkswagenstiftung
| Short description | |
| The corpus contains anonymized german court decisions from German criminal procedures from the years 2015 to the beginning of 2020. The court decisions are published by the Federal Court of Justice (BGH). The court decisions were crawled directly from the website of the case law database and are available in HTML format for further work. The source for the documents in the case law corpus is available under: hrr-strafrecht.de. |
|
Original documents 1.1.0. |
|
| Description: | |
| Since the criminal law court decisions were crawled from a web page, the original files are in HTML (PHP) format. |
|
| Download: | |
| Case Law Corpus 1.1.0 (zip, 33,8 MB) |
|
Only case law text 1.2.0. |
|
| Description: | |
| In this corpus there are only the case law texts without metadata. Sentence segmentation was performed. Since legal texts often use abbreviations, many sentence segmentations were incorrect. These incorrectly segmented sentences were recombined. For this purpose, first the sentence tokenizer from the NLTK package (nltk.org/api/nltk.tokenize.html) was trained on legal texts and then applied. Then, a manually created list of legal abbreviations was used to recombine incorrectly separated sentences. |
|
| Download: | |
| Case Law Corpus - Sentences 1.2.0 (zip, 18,5 MB) |
|
Tokenized case law sentences 1.3.0. |
|
| Description: | |
| This corpus contains the tokenized sentences from corpus 1.2.0. In addition to the tokens, the lemma and part-of-speech tags are included. Tokenization was performed using the word tokenizer from the NLTK package (nltk.org/api/nltk.tokenize.html). The lemmatization and one part-of-speech tagging was done with the HanTa tagger (github.com/wartaal/HanTa, C. Wartena) an additional part-of-speech tagging was done with the TreeTagger (cis.uni-muenchen.de/~schmid/tools/TreeTagger/, H. Schmidt). |
|
| Download: | |
| Case Law Corpus - Tokens 1.2.0 (zip, 39,4 MB) |
|
| Application area: | |
| Linguistic Resources, Legal Analyses, POS Tagging, Text Mining, Information Extraction, ... |
|
| Short description: | |
| This corpus contains contracts of the Hamburg City Administration and the Bremen City Administration. Some cooperation agreements between universities are also included. Among these contracts are several contracts that universities have concluded with external service providers. All contracts are available in PDF format. The contracts in this corpus are from the years 2014 to 2019 and are publicly available under the Data License Germany Attribution 2.0 or Data License Germany Zero Version 2.0 license. Sources for Contract corpus: City administration of Hamburg , City administration of Bremen (Keyword: "Vertrag") , Cooperation contracts between universities and also between universities and service providers: We searched specifically for contract files on university websites and added them to Contract corpus. |
|
Original contracts 2.1.0. |
|
| Description: | |
| The documents in this corpus are in PDF format. Text recognition (OCR technology from Image Recognition Integrated Systems S.A.) was performed on the files by Adobe Acrobat Reader. |
|
| Download: | |
| Contract Corpus 2.1.0 (7z, 5,44 GB external link) |
|
Cleaned and corrected contracts 2.2.0. |
|
| Description: | |
| The contract texts had to be extracted, cleaned and prepared for further processing.
The quality of the scanned contracts from the city administrations is not so good. There are documents with a lower scanning resolution, pages have been scanned at different angles, and so on. Moreover, all information that represents personal data has been blacked out. In this corpus, the texts have many OCR errors that needed to be cleaned up. In addition to OCR correction, word separations at the end of lines are also corrected. Then sentence segmentation was performed. Since legal texts often use abbreviations, many sentence segmentations were incorrect. These incorrectly segmented sentences were recombined. For this purpose, first the sentence tokenizer from the NLTK package (nltk.org/api/nltk.tokenize.html) was trained on legal texts and then applied. Then, a manually created list of legal abbreviations was used to recombine incorrectly separated sentences. |
|
| Download: | |
| Contract Corpus - Sentences 2.2.0 (Rar, 23,2 MB) |
|
Tokenized contract sentences 2.3.0. |
|
| Description: | |
| This corpus contains the tokenized sentences from corpus 2.2.0. In addition to the tokens, the lemma and part-of-speech tags are included. Tokenization was performed using the word tokenizer from the NLTK package (nltk.org/api/nltk.tokenize.html). The lemmatization and one part-of-speech tagging was done with the HanTa tagger (github.com/wartaal/HanTa, C. Wartena) an additional part-of-speech tagging was done with the TreeTagger (cis.uni-muenchen.de/~schmid/tools/TreeTagger/, H. Schmidt). |
|
| Download: | |
| Contract Corpus - Tokens 2.3.0 (Rar, 44,3 MB) |
|
| Application area: | |
| Linguistic Resources, Legal Analyses, POS Tagging, Text Mining, Information Extraction, ... | |
Niedersächsischen Ministeriums für Wissenschaft und Kultur
Förderinitiative: Niedersächsisches Vorab
Förderlinie: Geistes- und Kulturwissenschaften
– digital: Forschungschancen,
Methodenentwicklung und
Reflexionspotenziale
